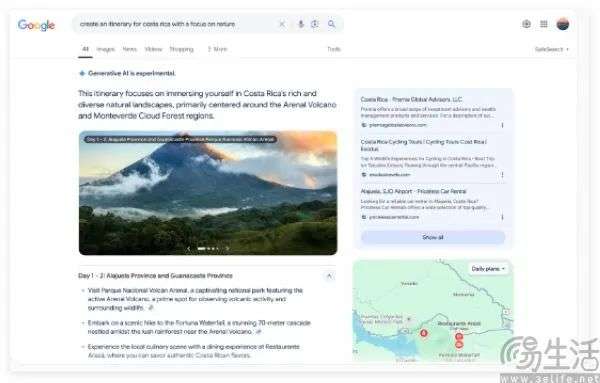
谷歌上线AI旅行功能,Gemini也要养家糊口了
谷歌上线AI旅行功能,Gemini也要养家糊口了随着DeepSeek R1、OpenAI GTP-4o、Antropic Claude3.7、xAI Grok3纷至沓来,AI大模型已然变成巨头的游戏,“百模大战”也成为了过去式。到了2025年,让用户先把AI用起来,也已经成为了一众厂商的共识。
来自主题: AI资讯
9545 点击 2025-04-04 10:37
 搜索
搜索
随着DeepSeek R1、OpenAI GTP-4o、Antropic Claude3.7、xAI Grok3纷至沓来,AI大模型已然变成巨头的游戏,“百模大战”也成为了过去式。到了2025年,让用户先把AI用起来,也已经成为了一众厂商的共识。
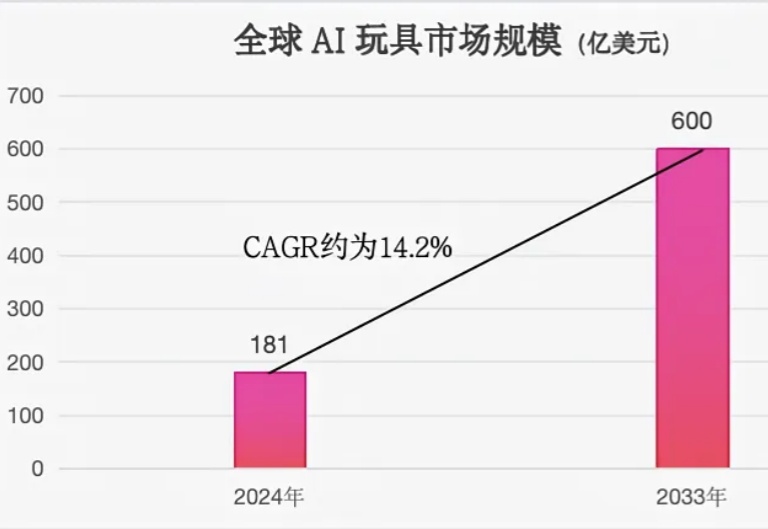
2025 年,DeepSeek 爆火带动传统产品的智能化升级,如传统玩具向 AI 玩具转型。央视新闻调查数据显示,2025 年 1 月,国内某电商平台面向 3-6 岁儿童的 AI 早教玩具销量环比增长 6 倍。咨询公司 IMARC 的预测数据显示,2024 年全球 AI 玩具市场规模已达 181 亿美元,预计到 2033 年将增长至 600 亿美元。

众所周知,DeepSeek R1 这种模型在推理任务上很能打,尤其是在数学和编程这些逻辑性强的领域。那么我们能直接把这种强大的推理能力搬到 DeepSearch 这种需要动态规划、多轮交互的深度搜索场景里吗?
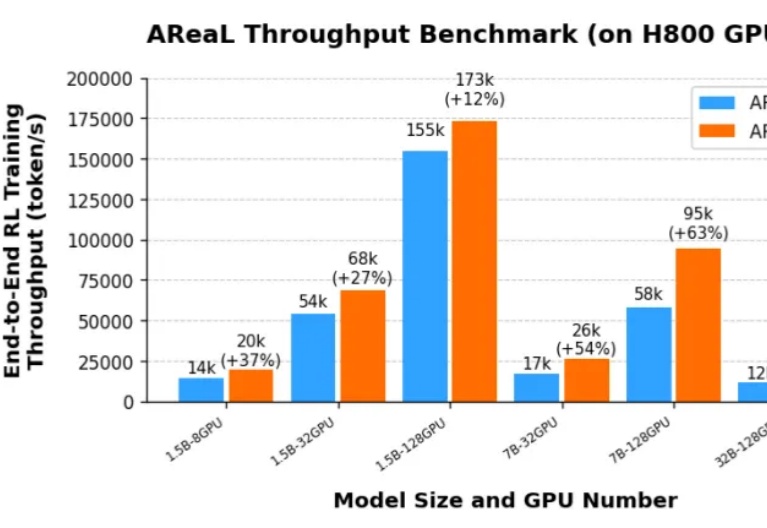
由于 DeepSeek R1 和 OpenAI o1 等推理模型(LRM,Large Reasoning Model)带来了新的 post-training scaling law,强化学习(RL,Reinforcement Learning)成为了大语言模型能力提升的新引擎。然而,针对大语言模型的大规模强化学习训练门槛一直很高:
AI社区掀起用大模型玩游戏之风!例如国外知名博主让DeepSeek和Chatgpt下国际象棋的视频在Youtube上就获得百万播放,ARC Prize组织最近也发布了一个贪吃蛇LLM评测基准SnakeBench。

晚点:过去将近 6 个月,AI 领域最重要的两件事,一是 OpenAI 去年 9 月 o1 发布,另一个是近期 DeepSeek 在发布 R1 后掀起全民狂潮。我们可以从这两个事儿开始聊。你怎么看 o1 和 R1 分别的意义?

DeepSeek 今年春节火遍中国之后,腾讯是第一个全线产品尽数接入的巨头,从微信、QQ 到腾讯自己的 AI 助手元宝和才上线几个月的工作台产品 ima。这被认为是腾讯 AI 投入爆发的开始。

685B的DeepSeek-V3新版本,就在昨夜悄悄上线了。参数量685B的V3,代码数学推理再次显著提升,甚至代码追平Claude 3.7,网友们实测后大呼强到离谱!有人预测说,按照此前的节奏,DeepSeek-R2大概率几周内就将上线。

DeepSeek V3升级了,新版本V3-0324。

DeepSeek深夜偷袭。昨天晚上,他们的v3模型,有了一波更新,版本号到了DeepSeek-V3-0324,而且是直接开源的。